
【并发容器】同样是线程安全的, ConcurrentHashMap 与 Hashtable 到底有什么区别呢?
大家好,我是Coder哥,在技术日新月异的今天,真正应该花费时间学习的是那些不变的编程思想,上一章 【并发容器】为什么Map桶中超过8个才转为红黑树?】 聊了为什么Map桶中超过8个才转为红黑树?,我们本章聊一下同样是线程安全的, ConcurrentHashMap 与 Hashtable 到底有什么区别?
本章节,我们将深入分析同样是线程安全的集合类 ConcurrentHashMap 和 Hashtable 到底有什么区别。总体上讲两者在多个方面存在显著不同,包括出现的版本、线程安全的实现方式、性能表现以及迭代时的行为。本文从以下四个角度详细解析它们的差异:
- 在JDK中出现的版本不同。
- 线程安全的实现策略不同。
- 性能上各有千秋。
- 迭代时的修改行为不同。
- 总结
在JDK中出现的版本不同。
两个容器出现的版本是不一样的。
- Hashtable: 诞生于 JDK 1.0,早期的 Java 集合类之一。在 JDK 1.2 后,它实现了 Map 接口,成为集合框架的一员。
- ConcurrentHashMap: 引入于 JDK 1.5,专为多线程环境设计,并对 Hashtable 的性能和使用体验进行了显著优化。
ConcurrentHashMap 是为现代并发场景而生的,是对 Hashtable 的迭代升级。
线程安全的实现策略不同。
ConcurrentHashMap 和 Hashtable 它们两个都是线程安全的,但是实现的策略是不一样的。 Hashtable 的线程安全实现是依赖 synchronized关键字,Hashtable 的方法几乎都被 synchronized 修饰,以保证线程安全。例如,clear() 方法的源码如下:
public synchronized void clear() {
Entry<?,?> tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
}
从代码中可以看出, clear() 方法是被 synchronized 关键字所修饰的,同理其他的方法例如 put、get、size 等,也同样是被 synchronized 关键字修饰的。之所以 Hashtable 是线程安全的,是因为几乎每个方法都被 synchronized 关键字所修饰了,这也就保证了线程安全。Collections.SynchronizedMap(new HashMap()) 的原理和 Hashtable 类似,也是利用 synchronized 实现的。
而ConcurrentHashMap 的线程安全实现则是基于分段锁和 CAS,在 JDK 8 中,ConcurrentHashMap 的核心实现依赖以下技术:
- CAS(Compare-And-Swap): 无锁操作,用于实现高效的并发更新。
- 分段锁: 仅对必要的部分加锁,而不是锁住整个结构,从而减少锁竞争。
- Node 节点: 链表与红黑树的动态切换,在高并发下进一步提升性能。
以下是其结构的示意图: 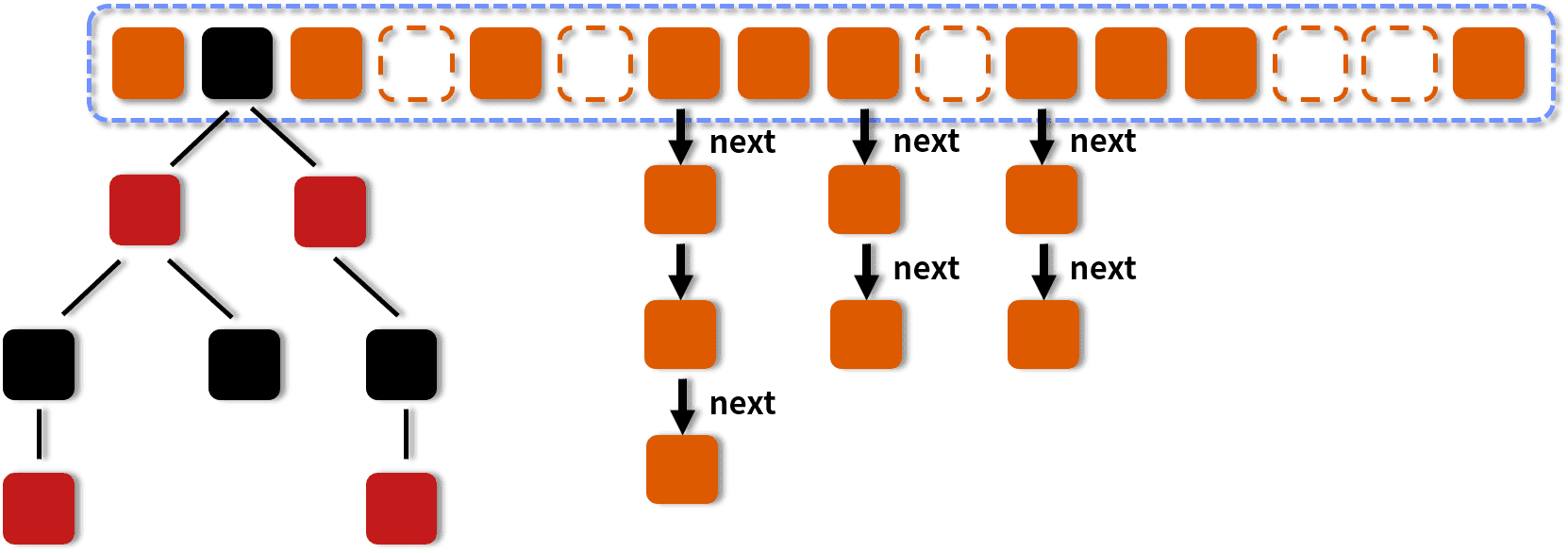
ConcurrentHashMap 的实现更加精细,本质上它实现线程安全的原理是利用了 CAS + synchronized + Node 节点的方式,避免了 synchronized 的大范围锁定,是高性能线程安全的集合选择。
性能上各有千秋。
实现方式不一样,注定性能也是不同的。 Hashtable 的性能瓶颈 Hashtable 的所有操作都需要锁住整个对象,即使是只读操作,也可能因锁争用而阻塞。在线程数量增加时,其性能急剧下降,不仅如此,还会带来额外的上下文切换等开销,甚至可能低于单线程执行的情况。
ConcurrentHashMap 的高效并发,由于ConcurentHashMap 基于分段锁和CAS,有以下的优势。
- 分段锁: 锁的粒度更小,只对操作的部分数据结构加锁,而非全局锁。
- CAS: 无锁读操作,大部分读操作使用 CAS 实现,不需要锁定。
- 并发效率显著提升: 特别是在高并发场景下,其吞吐量远高于 Hashtable。
ConcurrentHashMap 在性能上的优势非常明显,尤其是在多线程场景中。
迭代时的修改行为不同。
除了并发实现上,迭代的行为也不一样: Hashtable 的迭代限制
- 行为: Hashtable 在迭代时禁止结构性修改(如添加、删除元素)。否则会抛出 ConcurrentModificationException。
- 原理: modCount 变量记录修改次数,迭代器的 next() 方法会检查 modCount 是否变化,迭代器的 next() 方法的代码如下:
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
在这个 next() 方法中,会首先判断 modCount 是否等于 expectedModCount。其中 expectedModCount 是在迭代器生成的时候随之生成的,并且不会改变。它所代表的含义是当前 Hashtable 被修改的次数,而每一次去调用 Hashtable 的包括 addEntry()、remove()、rehash() 等方法中,都会修改 modCount 的值。这样一来,如果我们在迭代的过程中,去对整个 Hashtable 的内容做了修改的话,也就同样会反映到 modCount 中。这样一来,迭代器在进行 next 的时候,也可以感知到,于是它就会发现 modCount 不等于 expectedModCount,就会抛出 ConcurrentModificationException 异常。
ConcurrentHashMap 的灵活性
- 行为: 允许在迭代期间修改内容,且不会抛出 ConcurrentModificationException。
- 实现: 其迭代器使用“弱一致性”策略:迭代过程中,新增或修改的元素可能会被迭代器看到,也可能不会看到,但不会抛异常。
所以对于 Hashtable 而言,它是不允许在迭代期间对内容进行修改的。相反,ConcurrentHashMap 即便在迭代期间修改内容,也不会抛出ConcurrentModificationException,ConcurrentHashMap 的设计更适合动态更新的并发场景。
总结
| 对比维度 | Hashtable | ConcurrentHashMap |
|---|---|---|
| 出现版本 | JDK 1.0 | JDK 1.5 |
| 线程安全实现方式 | 全局锁(synchronized) | 分段锁 + CAS + Node 节点 |
| 性能 | 高并发下性能差,锁争用严重 | 高效并发,锁粒度更小 |
| 迭代时的修改行为 | 不允许修改,抛出 ConcurrentModificationException | 允许修改,无异常,弱一致性 |
在我们平时开发中,如果需要线程安全的集合类,ConcurrentHashMap 是更优的选择。相较之下,Hashtable 已逐渐被淘汰,仅适用于一些历史遗留的场景。
书籍推荐:
《计算机内功修炼系列》:https://www.todocoder.com/pdf/jichu/001001.html
《Java编程思想》 :https://www.todocoder.com/pdf/java/002002.html
《Java并发编程实战》 :https://www.todocoder.com/pdf/java/002004.html